在用户空间的程序有的时候可能需要和内核进行消息交互,内核需要提供一种机制来满足用户空间程序的这一需求。虽然系统调用确实提供了一个用户空间程序和内核的交互机制,但是系统调用在一些轻量级的交互上未免显得过于重量级。为此,Linux 内核在用于请求特定信息的经典系统调用以外,还提供了另外的几种用户空间和内核的通信接口,分别是procfs,sysctl,sysfs,ioctl以及 netlink 套接字。procfs和sysfs都是虚拟文件系统,这一部分暂且不提,sysctl对应的是/proc/sys文件,实际上是一个内核变量,这一部分也不在这里详谈,ioctl则是在设备控制上做的工作,细说起来估计也能单开一篇文章了。本文主要还是对 Netlink 的机制做一个简单的概括与总结。
Netlink 是什么?为什么是 Netlink?
按书里的描述总结来看,Netlink 是一个允许内核内部以及内核与用户空间的程序相互进行通信的消息传输机制,是对标准套接字实现的拓展。在 Netlink 诞生之前,一般使用 procfs、sysfs 和 ioctl 来进行内核和用户空间程序之间的数据交互。相比其他机制,Netlink 具有一些更明显的优势:
- 任何一方都不需要轮询,像 procfs 和 sysfs 这类利用文件进行信息传递的机制,用户空间程序需要不断轮询文件来及时获取信息的更新。
- 系统调用和 ioctl 也能够从用户空间向内核传递信息,但是相比 Netlink 更难以实现。另外,使用 Netlink 不会与其他的内核模块产生冲突,但模块和系统调用显然配合得不是很好。(这里是《深入 Linux 内核架构》的原话,不过我还不是很理解)
- 内核可以直接向用户层发送信息,而不需要用户空间程序事先向内核请求。这一点使用文件也能做到,但是系统调用和 ioctl 显然不能够做到。
- 用户只需要使用标准的套接字和内核进行交互。
内核不仅支持单播消息,也支持多播,并且 Netlink 的工作方式是异步的。Netlink(3) 和 Netlink(7) 两个手册页提供了 Netlink 机制的文档,其中 netlink(3) 描述了内核中用于操作、访问、创建 Netlink 数据报的宏。手册页 netlink(7) 包含了有关 Netlink 套接字的一般性信息,并给出了这里其的数据结构的文档。另外,/proc/net/netlink里面包含了关于当前活动的 Netlink 连接的一些信息。
Netlink 是怎么工作的?
从创建说起
从用户空间程序来看,Netlink 和普通的 BSD 套接字长得很像。在创建 Netlink 套接字的时候,也需要用socket()函数创建一个 socket 描述符,再为其分配一个地址。创建 Netlink 套接字的时候,需要指定 family 为AF_NETLINK,而 type 既可以指定为SOCK_RAW,也可以是SOCK_DGRAM,最终创建的都是一个netlink_sock对象。至于 protocol,根据该 Netlink 套接字的用途,有不同的选择,具体可以看《深入 Linux 内核架构》第 650 页或者是 Netlink 的手册。
Netlink 用到的套接字地址结构体sockaddr_nl和 socket 用的sockaddr_in非常像。
struct sockaddr_nl
{
sa_family_t nl_family; /* AF_NETLINK */
unsigned short nl_pad; /* 0 */
__u32 nl_pid; /* 端口 ID */
__u32 nl_groups; /* 多播组掩码 */
};
结构体的前两项是固定的,nl_pid是 Netlink 套接字的单播地址,一般用户空间程序会将其设置为进程 id。如果用户空间程序在调用bind()之前将其设置为 0,或者不进行设置,内核中的netlink_autobind()将会尝试将其设置为当前线程的 pid。如果一个用户程序需要用到多个 Netlink 套接字,则其nl_pid不能发生冲突。nl_groups是一个 bitmap,表示了该套接字的组播组掩码。
Netlink 的消息有一定的格式,每个消息分为 header 和 payload 两部分,header 的格式由struct nlmsghdr规定,主要包含如下内容:
struct nlmsghdr
{
__u32 nlmsg_len; /* 消息长度,包括首部和 padding 在内 */
__u16 nlmsg_type; /* 消息内容的类型 */
__u16 nlmsg_flags; /* 附加的标志 */
__u32 nlmsg_seq; /* 消息序列号 */
__u32 nlmsg_pid; /* 发送进程的端口 ID */
};
需要注意的是,因为 Netlink 消息需要对其到预先规定的字节边界,所以在载荷后面可能会有一些填充字节。
对于用户空间程序来说,Netlink 和套接字的表现一致,用户空间程序可以简单地利用套接字 API 来对内核进行交互。
与用户空间不同,内核中会利用netlink_kernel_create()函数进行 Netlink 套接字的创建。针对不同的场景,该函数需要不同的参数设置,包括了命名空间、Netlink 协议族、多播数目等等。如果需要处理来自用户空间的输入,则需要在创建 Netlink 套接字时,在netlink_kernel_cfg结构体中指定一个回调函数用于处理用户空间程序向内核发送的数据,如果没有指定回调函数,那么内核将无法接收来自用户空间的数据。
Netlink 在内核中的数据结构表现
下面讲一个我读到 Netlink 这一章产生的一个疑问,即 Netlink 在内核的对端是怎样的存在?按我的理解,除非发生中断,否则内核应该是不会主动运行的,那么按照传统的套接字的理解,套接字的两端在期望接收到对方的数据的时候都是阻塞的,内核又是不可能发生阻塞的,Netlink 套接字中数据的接收和处理是在什么时候执行的呢?在阅读了几本书上的内容,以及参考了网络上的一些博客之后,我有了一个大概的理解,但是因为近期时间有限,没有详细看过内核代码,不能够肯定自己的理解正确性,仅作为一个参考。
如果是按照套接字的方法直接去理解 Netlink,直观上就会存在上面描述的问题,不过其实核心的答案就在于,Netlink 只是套了一层套接字的皮,实际上由于其双方的内容仅在单台计算机上面进行交换,那么这个信息传递的过程其实就是内核中数据结构的内存拷贝而已。下面给一张来自 图解 Linux Netlink的图:
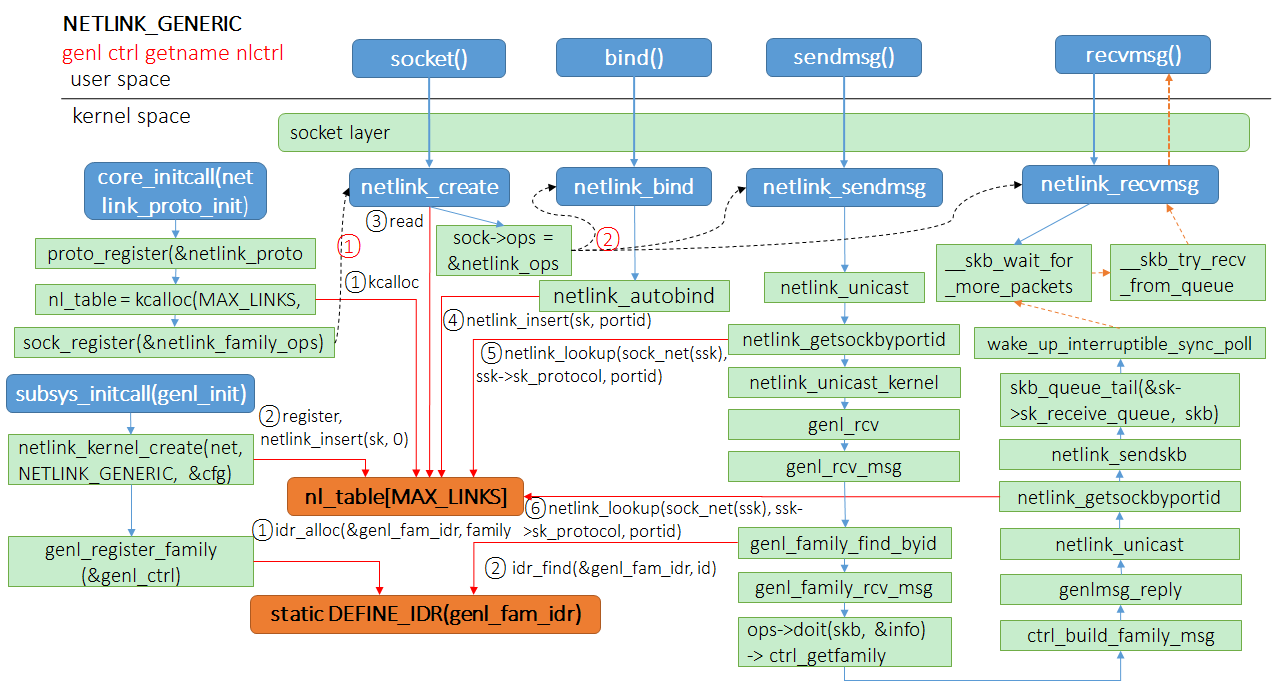
Netlink 套接字初始化
Netlink 套接字在内核中有一个非常重要的数据结构,即struct netlink_table nl_table,这是一个 hash 链结构,大小由一个宏MAX_LINKS规定,值为32。这个值是和 Netlink 协议族的数量对应的,每个 Netlink 协议族会在这个数组里面占用一项。目前在 Linux 内核里面共定义了 0~22 共 22 个协议族(17 号协议族为 DM Events 预留)。在内核启动阶段,Netlink 子系统会调用函数向内核网络协议栈注册 Netlink 协议,用于辅助在创建用户空间套接字的时候指定套接字的大小。然后内核开始初始化nl_table数据结构,所有创建的 Netlink 套接字都要将自身插入到这个表里面(用户空间套接字在 bind 系统调用的时候调用netlink_insert()插入该表,而内核套接字则在创建的时候调用netlink_insert()插入该表),方便之后在发送数据的时候快速通过netlink_lookup()函数定位目标套接字。在此之后,内核会注册 Netlink 协议族套接字操作函数块,设置好对 Netlink 套接字进行操作的时候使用的函数。最后初始化rtnetlink套接字,这个套接字属于NETLINK_ROUTE协议族,用于路由、邻接、链路消息和其他网络子系统消息。至于为什么要在这个时候就初始化rtnetlink套接字,内核的注释里面说这个套接字可能会被较早使用。
创建套接字并插入 nl_table
用户空间以及内核中的套接字创建可以参考上面的描述,但上面的描述是处于一个调用者的角度来看。从内核的角度来看,每个 socket 最终都要挂到nl_table里面方便检索。
向 Netlink 套接字发送数据
向 Netlink 套接字发送数据的时候调用的是通用的套接字 API,不过这里实际的调用函数是之前初始化的时候预先设置的 Netlink 处理函数。这里会调用netlink_sendmsg()函数,这个函数会做一系列检测,是由单播或者多播发送。如果使用单播发送(netlink_unicast()),内核会使用netlink_getsockbyportid()从 nl_table 里面获取目标套接字,检测目标套接字是否是内核套接字,如果不是内核套接字,将skb通过netlink_attachskb()和netlink_sendskb()函数进行检测和发送(netlink_attachskb()函数只是检测当前 skb 能不能发送到目标套接字,但是并不会实际进行发送)。netlink_sendskb()会将skb插入目标套接字的接收列表中,并调用目标套接字的sk_data_ready()函数。如果目标套接字是内核套接字,则会调用netlink_unicast_kernel()函数,如果预先在该类型的协议簇上设置了 input 回调函数,则会调用该函数来处理接收到的内容。否则就什么也不做。这就解释了内核在什么时候接收并处理消息的问题,内核并不会在某个 Netlink 套接字上面阻塞并等待消息,因为 Netlink 所传递的信息本身就是通过内核进行交付的(在用户空间程序中,体现为通过系统调用请求内核交付),内核在交付的过程中,发现这个消息的目的套接字是自己,那么就直接调用实现注册的回调函数处理了,甚至连都不需要将skb放到等待队列里面。需要注意的是,由于发送到内核的 Netlink 消息是直接在中断上下文里面进行处理的,因此用于处理 Netlink 消息的 input 回调函数的处理事件不能太久。如果需要在 input 中进行大量耗时操作,最好的方法是启用一个内核线程来专门处理这个工作。
从 Netlink 套接字接收数据
相比发送数据,接收数据就比较直接了。内核自己并不需要处理接收数据的逻辑,因为内核本身就是一个代码库,哪里需要调哪里。需要接收数据的都是线程,不管是内核线程还是用户线程,在接收数据前就只需要调用套接字的接口阻塞在套接字的等待队列上面,内核在将消息传递到目标套接字对应的缓冲区后会自动唤醒目标套接字上面阻塞的线程。
我能拿 Netlink 做什么?
现在看下来,Netlink 的机制已经比较明了。它基于现有的套接字机制,建立了一个很好的用户空间和内核交互的通信机制,相比其他的通信机制,Netlink 更为灵活好用。但是以上的介绍都是基于实现机制的角度来描述 Netlink 的,从策略的角度来讲,我们能利用 Netlink 机制实现什么工作呢?这些工作又该如何去实现呢?
Netlink 协议族与功能一一对应
如果说我们将用户空间和内核之间进行通信的 Netlink 套接字按照不同的类型进行分类,这个分类就是 Netlink 协议族,而 Netlink 协议族也是nl_table哈希链中用于索引 Netlink 套接字的 key。之所以使用 Netlink 协议族来对不同功能的 Netlink 套接字进行区分,个人猜测可能是出于内核处理效率优化的原因。在内核创建的对应不同 Netlink 协议族的 Netlink 套接字中,分别设计了不同的 input 回调函数用于处理用户空间发送过来的信息(具体的逻辑可以参考上面的描述)。用户空间的程序可以通过指定一个 Netlink 协议族,来连接到一个指定的内核 Netlink 套接字,并通过向其发送消息,触发对应的回调函数来实现期望的功能。比较经典的协议族是NETLINK_ROUTE,该套接字用于内核和用户空间程序关于网络路由选择子系统、临界子系统、接口设置消息、防火墙消息、Netlink 排队消息、策略路由消息以及众多其他类型的rtnetlink消息的交互。利用这个套接字,用户空间的程序可以用于创建、检索和删除不同类型的消息簇的信息,比如向路由选择表中添加和删除路由选择条目(iproute2 就是利用 Netlink 机制实现的)。
多路复用器——通用 Netlink 协议族
虽然上面的修改路由表例子比较直接,但其只是作为用户空间程序的角度来利用内核预置的 Netlink 机制。因为 Netlink 协议族是区分 Netlink 功能的关键,我们要在内核中增加自己需要的功能时,就需要为自己需要的功能创建一个新的 Netlink 协议族以与其他的 Netlink 协议族作出区分,利用自己的 input 回调函数来进行必要的交互。但是 Netlink 规定协议族最多不能超过MAX_LINKS,即 32 个。为了支持添加更多的通用协议簇,以提供更多样化的功能,Netlink 机制提供了一个通用的协议族NETLINK_GENERIC用来实现多路复用的目的。目前已经有许多内核子系统是基于通用 Netlink 协议族进行设计的,包括 ACPI 子系统、任务统计信息代码等,用户空间的例子则包括 hostapd、iw 等。
由于 Netlink 协议族需要进行多路复用的工作,其必然要有区分不同路内容的能力。通用 Netlink 按照 family 进行管理,如果用户希望使用通用 Netlink 完成某项功能,用户就需要自行注册自己定义的genl_family结构,内核则使用一个哈希表family_ht对已经注册的genl_family进行管理。每个genl_family需要有一个独特的id和一个独特的name,name一般由用户指定,而id交由内核自动生成。genl_family也需要注册自己的用户命令cmd处理函数,一个 family 可以支持多个不同的 cmd 命令(如果该通用 Netlink 协议族仅从内核向用户空间发送消息,则可以不实现)。这一点就很像创建一个其他 Netlink 协议族所需要的工作了,预先定义好一个对象,包含不冲突的,便于索引的索引号和一些用于处理收到的用户消息的回调函数,将其注册到内核系统中。
这里为什么同时使用
id和name呢?个人猜测是因为id作为一个数字,更方便在内核的数据结构中进行索引,但是用户在注册 family 的时候并不能预先知道内核中哪些 id 是空余的,因此需要先提供一个不容易冲突,且用户更容易记住的name字段,在注册时让内核自动寻找一个不冲突的id并与name相关联,之后用户再通过name向通用 Netlink 控制器查询对应的id,避免用户自行指定id可能产生的冲突以及name字段不方便索引的问题。
通用 Netlink 套接字的地址sockaddr_nl与普通的 Netlink 套接字并没有区别(即一般绑定 pid),而在nl_table中查找目标套接字亦是同样的方法。用户在向内核中自己预先注册的genl_family发送消息的时候,需要先向genl_ctrl族询问其注册的genl_family对应的id,将上述提及的nlmsghdr,即 Netlink 消息头中的nlmsg_type字段设置为对应的id号,再填充通用 Netlink 消息头,设置需要内核中已注册的genl_family执行的cmd。内核在接收到用户的通用 Netlink 协议后,会解析消息并封装成genl_info结构,便于令回调函数处理。回调函数会根据消息的nlmsg_type字段寻找对应的genl_family,调用预先注册的cmd处理函数返回。详细的逻辑和一个简单的例子可以参考这篇文章。基于以上的逻辑,我们就能够利用 Linux 的模块机制向内核中插入自己的 Netlink family,在内核中处理以及向用户空间传递提供自己需要的信息了。
后记
其实写这篇文章的核心驱动力,就是文中加粗的那段话回答的问题:都说 Netlink 的使用和套接字基本一致,但是内核又不可能阻塞等待套接字传来消息,Netlink 在内核端究竟是什么机制?手中的几本讲述 Linux 内核网络的书籍对 Netlink 都是简单地带过,而对《精通 Linux 内核网络》的前几章浅读让我觉得这本书似乎只是在堆砌数据结构的源代码,具体的机制则讲的模糊不清(尤其是通用 Netlink 方面),网络上几位大佬的博客倒是在这个 Topic 上要讲的更加细致入微,可惜的是,近几年这样优秀的博客是越来越少见了,而低质量的采集站和各种复制粘贴怪层出不穷,几乎要将搜索引擎淹没,不仅让人感叹,真是人心不古啊。
参考
- 《深入理解 Linux 网络技术内幕》
- 《精通 Linux 内核网络》
- 《深入 Linux 内核架构》
- netlink(3)
- netlink(7)
- 网络编程 socket 基本 API 详解
- 图解 Linux Netlink
- Linux 的 Netlink 机制
- Netlink 内核实现分析(二):通信
- Generic Netlink 内核实现分析(一):初始化
- af_netlink.c
- 深入理解 Linux 内核之内核线程(上)
- Linux 内核:设备驱动模型(4)uevent 与热插拔
- kobject_uevent.c